张蕾
AI 应用方向|工作流提效|AI产品经理
以好奇心探索 AI 边界,
以产品思维定义场景,
让 AI 能力服务于真实需求和具体流程。
一起创造一些有用的东西。
13132528079 | 506879016@qq.com
关于我
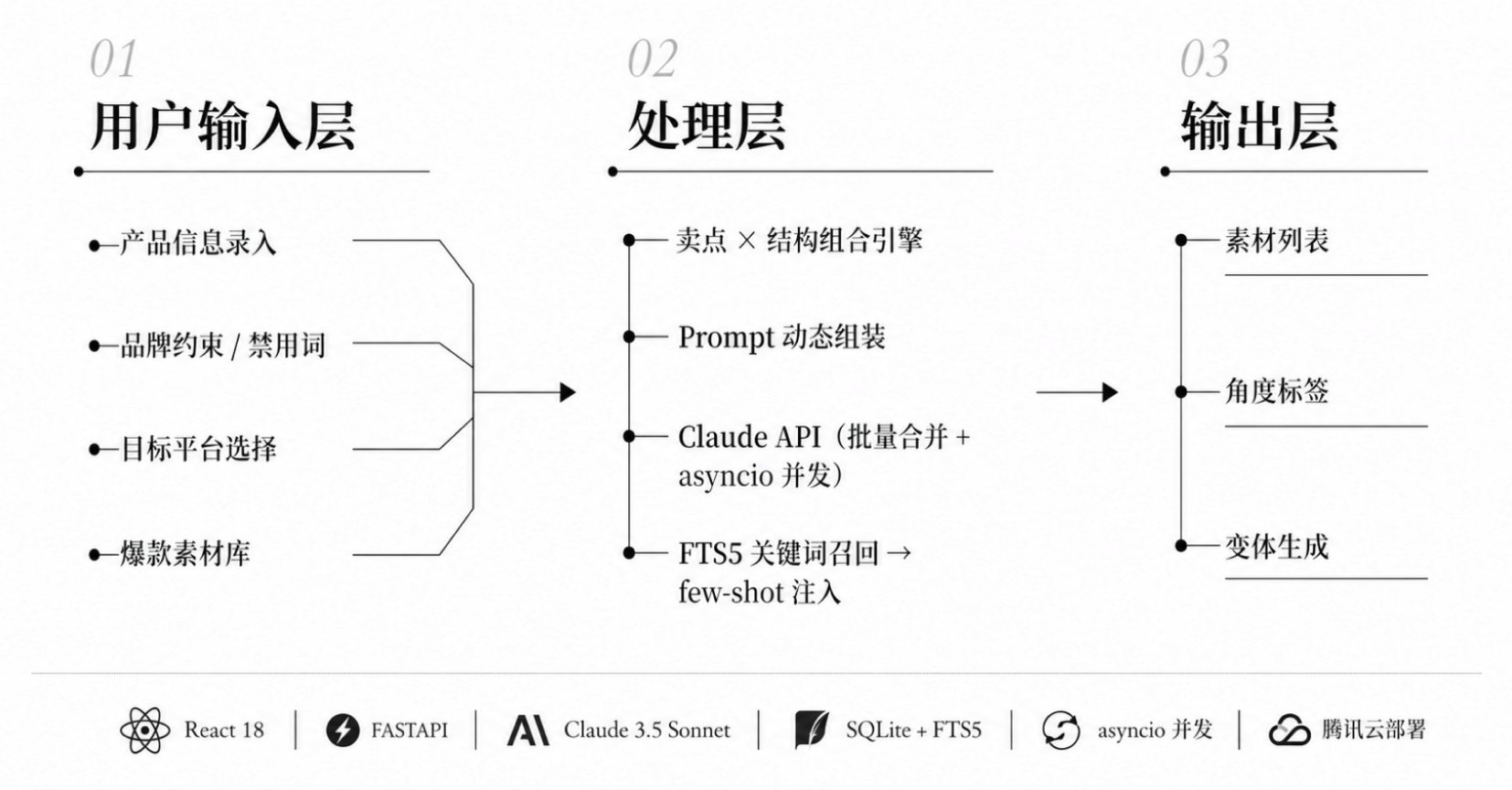
建筑学出身,习惯把复杂问题拆成可执行的结构。2023 年开始系统探索 AI 应用,vibe coding 出现后全面转向 AI 工具开发与工作流设计。
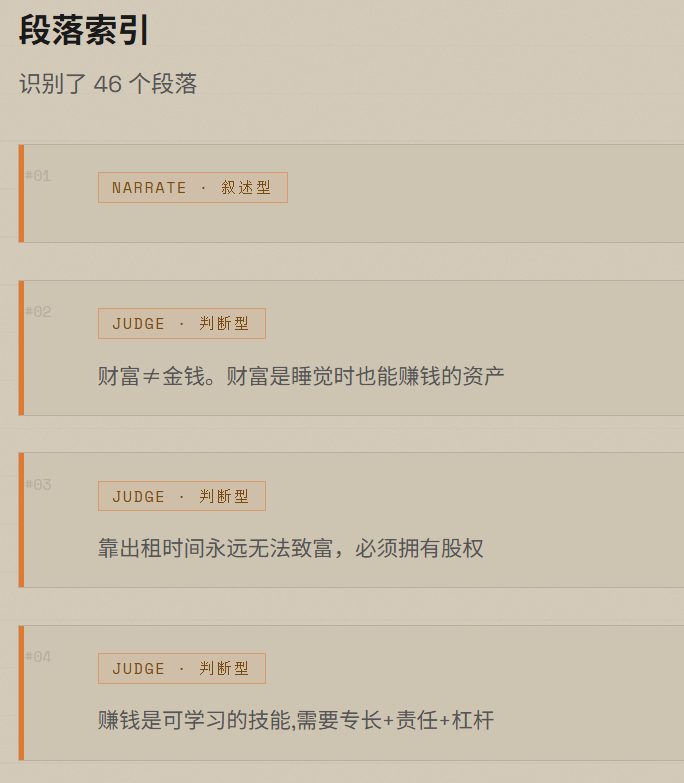
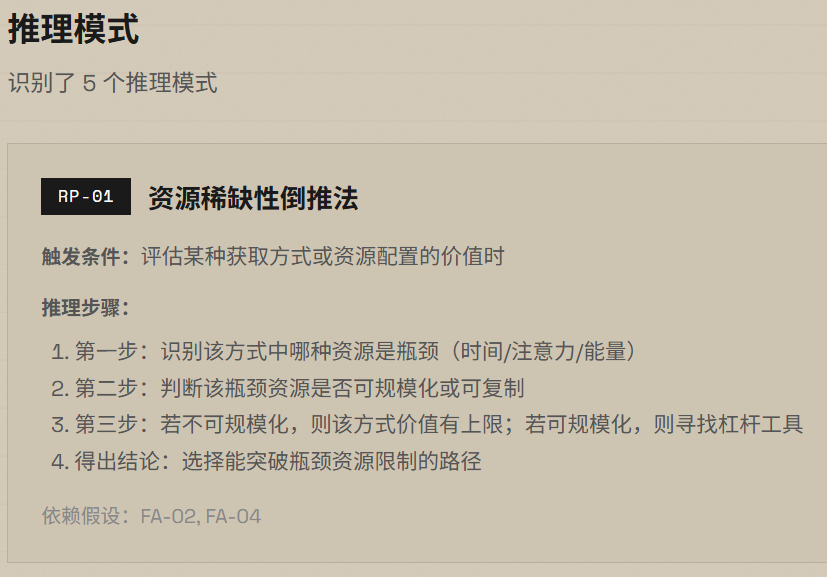
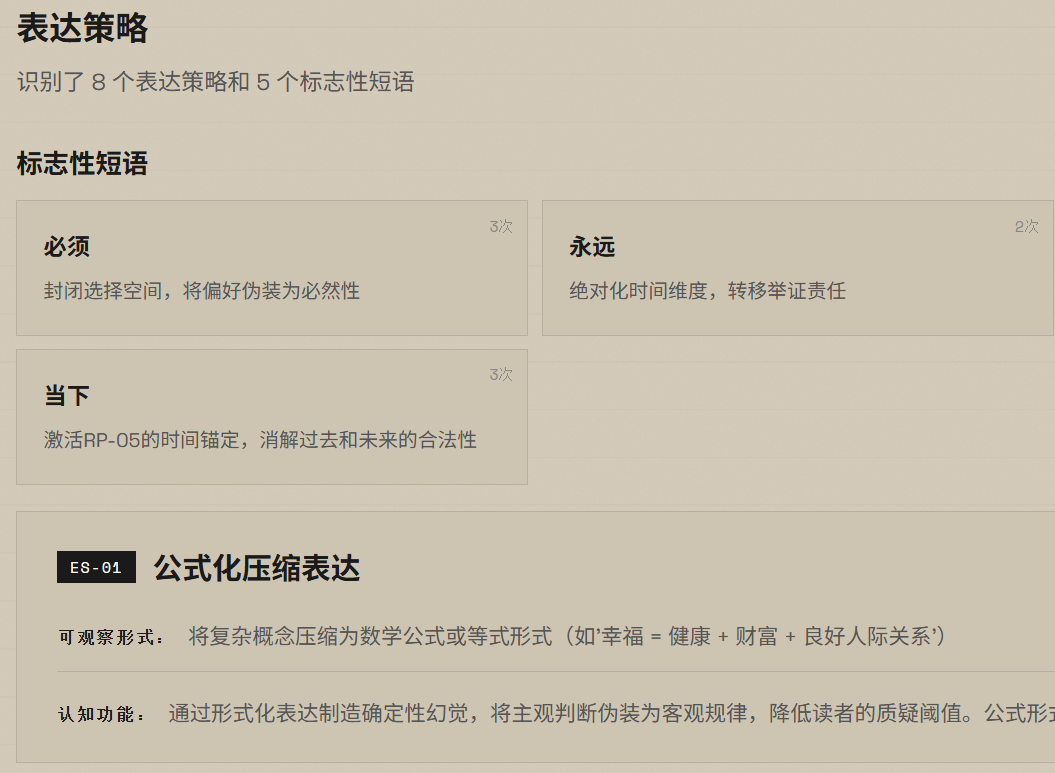
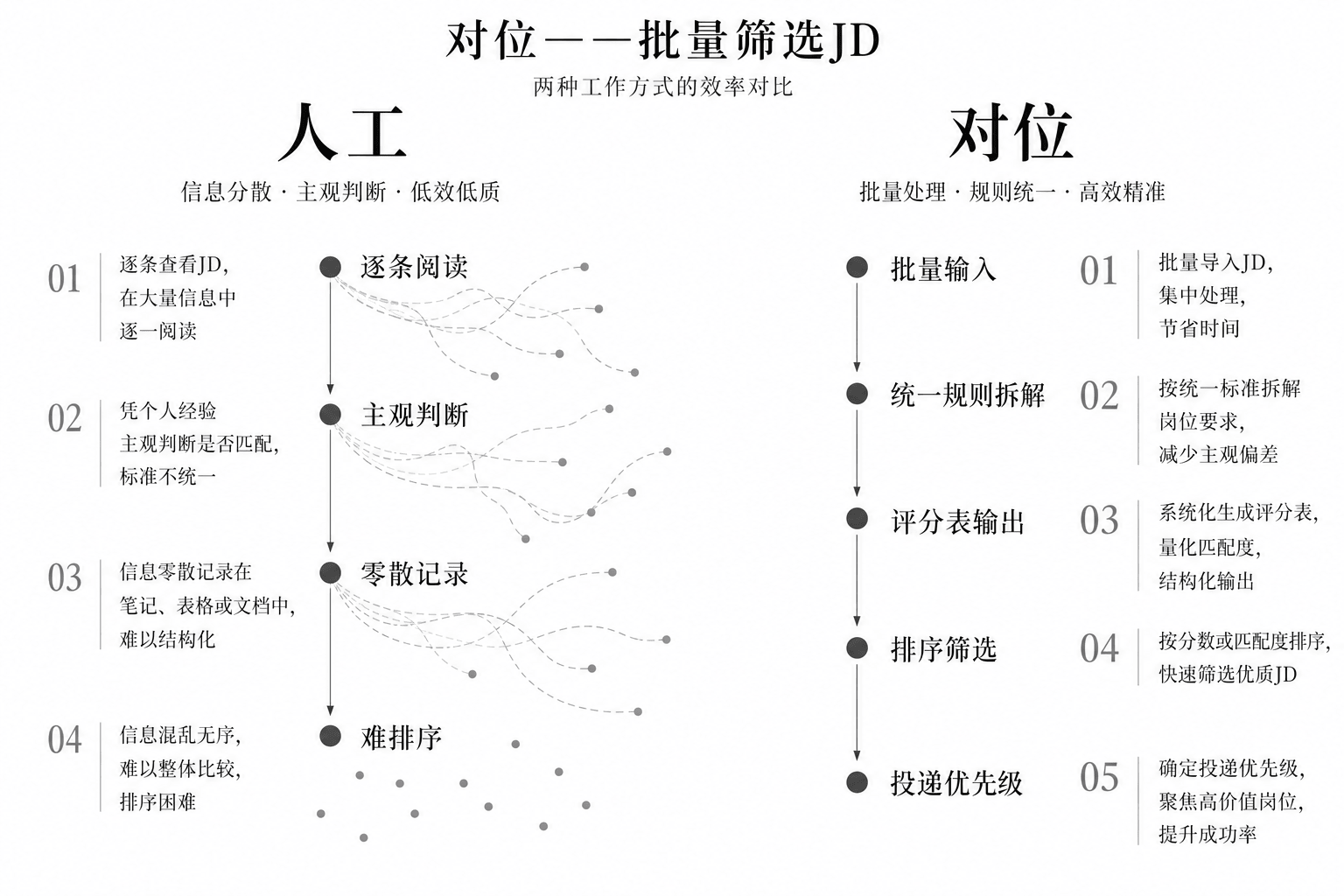
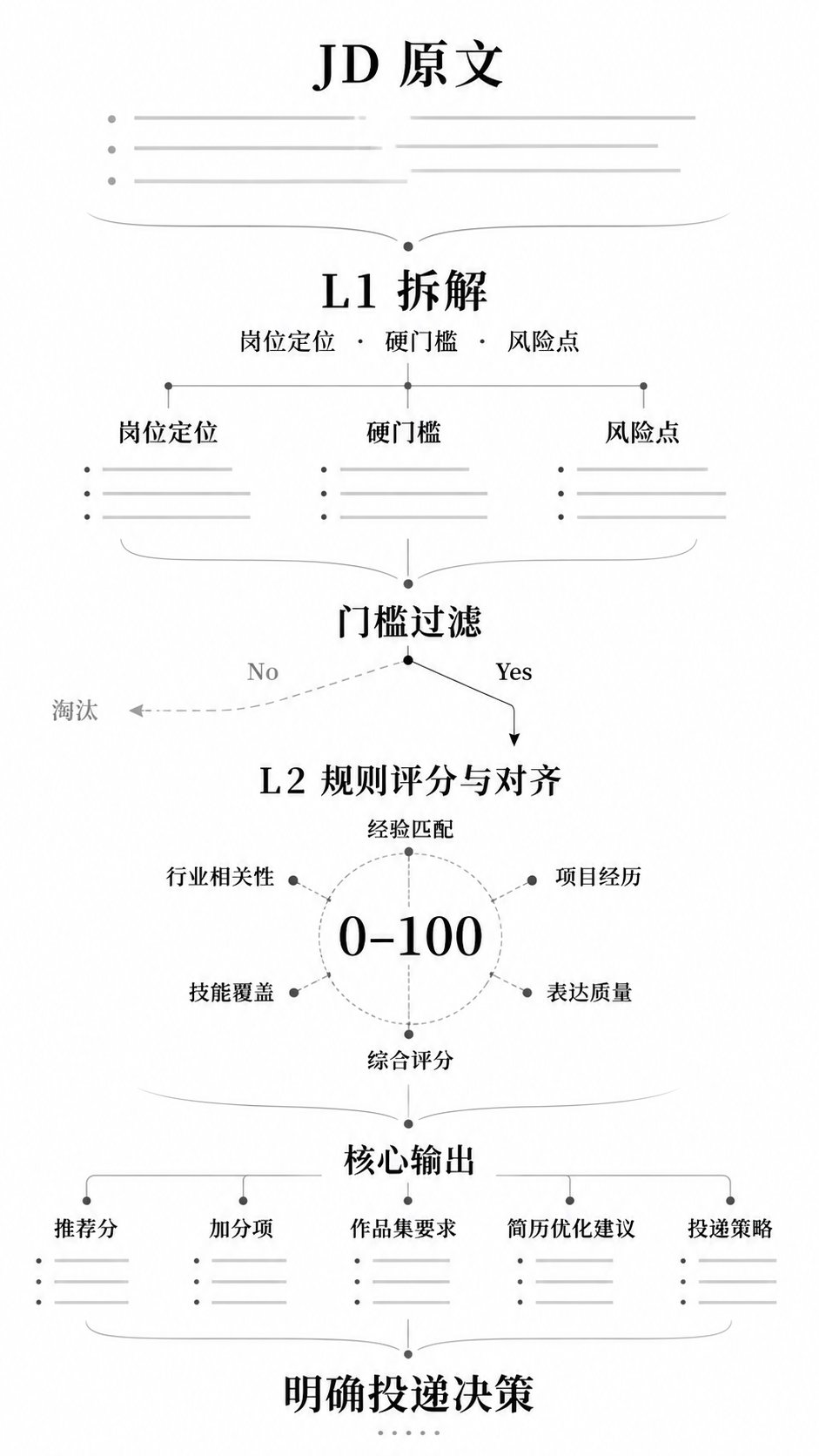
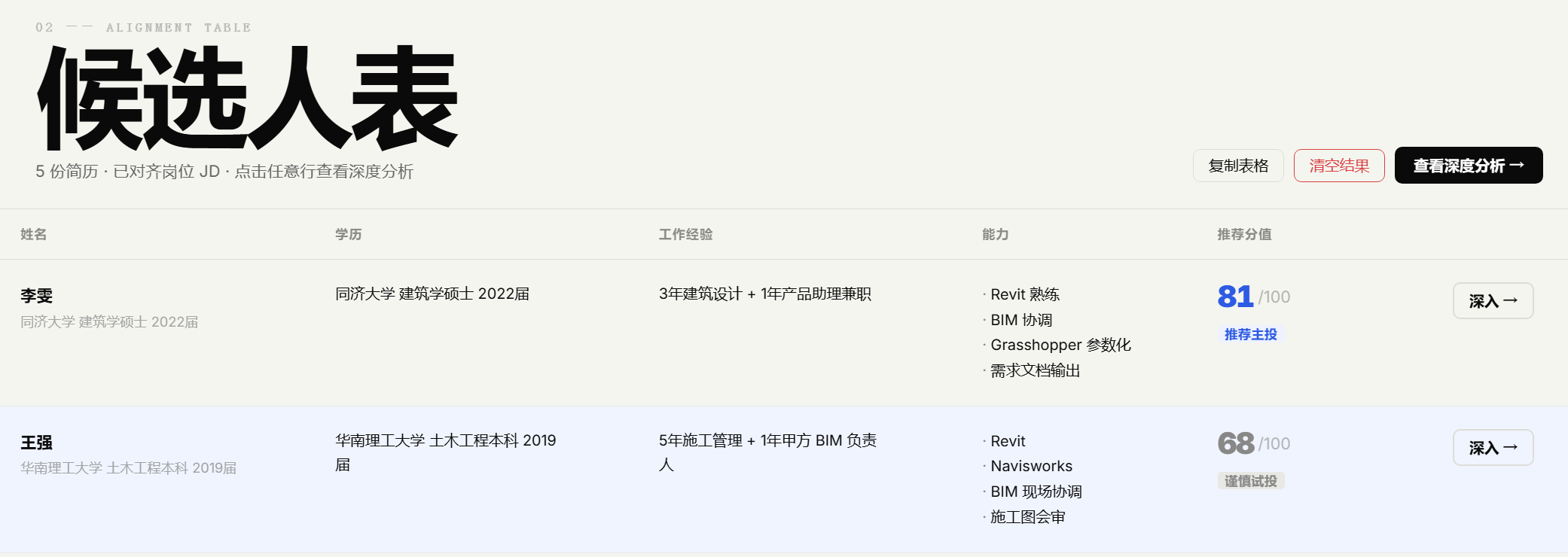
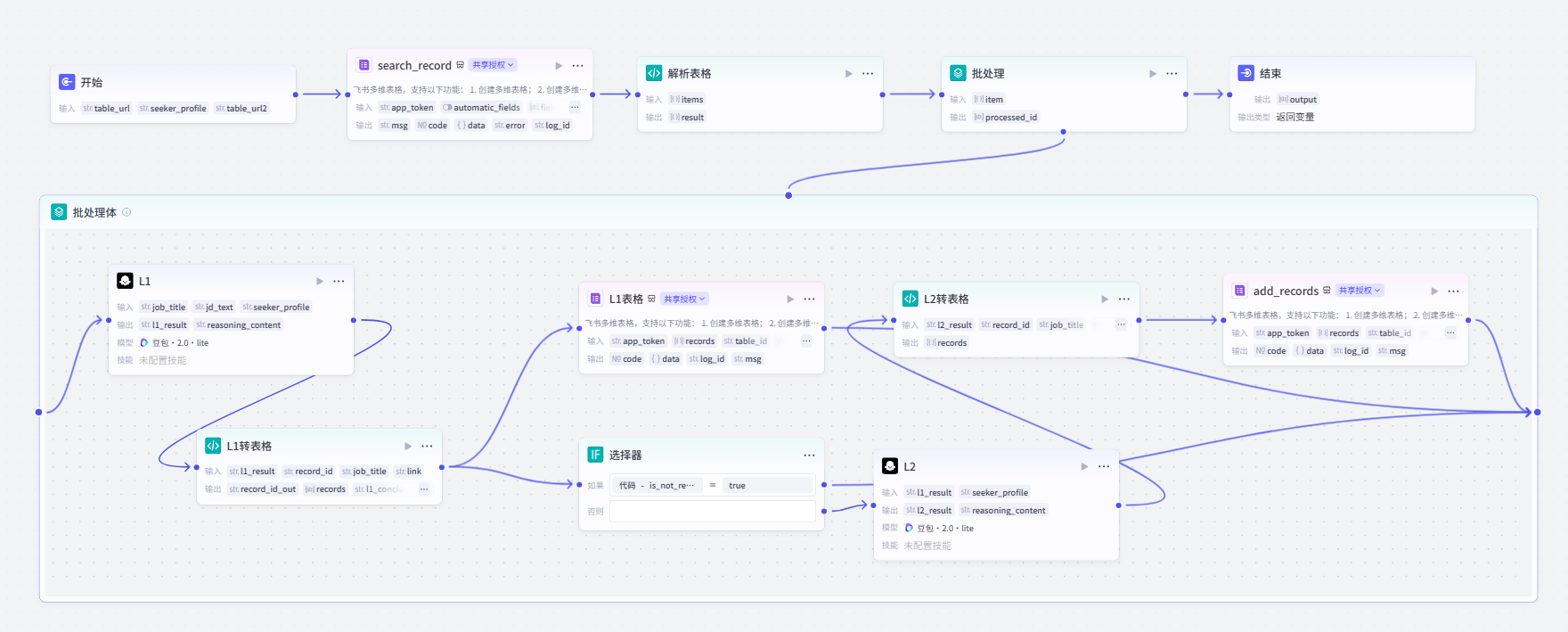
我做东西有一个原则:从自己的真实需求出发。对位是因为我自己在筛岗位,Mirror 是因为我自己要快速拆解别人的思维方式——先有痛点,再设计方案,做完自己用,不好用就迭代。这不是练手项目,是正在跑的工具。
我相信 AI 应用岗最核心的能力不是"会用工具",而是能看懂业务流程里哪些环节值得重构,然后把方案落地。6年的建筑设计经历锻炼了我需求拆解和方案迭代的能力;在小企业做管理运营,让我对业务流程中的低效环节有直觉。这两段经历加上现在的 AI 应用能力,就是我带到下一份工作里的东西。
目前在找 AI 应用方向、AI 产品经理、 工作流提效方向的岗位。把重复工作做成 AI 流程,把个人经验沉淀为团队资产,为真实工作流搭建可落地的 AI 工具,期待与您共事。
Contact : 13132528079 | 506879016@qq.com

关于我
建筑学出身,习惯把复杂问题拆成可执行的结构。2023 年开始系统探索 AI 应用,vibe coding 出现后全面转向 AI 工具开发与工作流设计。
我做东西有一个原则:从自己的真实需求出发。对位是因为我自己在筛岗位,Mirror 是因为我自己要快速拆解别人的思维方式——先有痛点,再设计方案,做完自己用,不好用就迭代。这不是练手项目,是正在跑的工具。
我相信 AI 应用岗最核心的能力不是"会用工具",而是能看懂业务流程里哪些环节值得重构,然后把方案落地。6年的建筑设计经历锻炼了我需求拆解和方案迭代的能力;在小企业做管理运营,让我对业务流程中的低效环节有直觉。这两段经历加上现在的 AI 应用能力,就是我带到下一份工作里的东西。
目前在找 AI 应用方向、AI 产品经理、 工作流提效方向的岗位。把重复工作做成 AI 流程,把个人经验沉淀为团队资产,为真实工作流搭建可落地的 AI 工具,期待与您共事。
13132528079(微信同号)
506879016@qq.com